Sub-Gaussian Mean Estimation in Polynomial Time
(loading loading loading – advance slide)
\(\newcommand{\R}{\mathbb{R}}\) \(\newcommand{\e}{\varepsilon}\) \(\newcommand{\cD}{\mathcal{D}}\) \(\newcommand{\poly}{\text{poly}}\) \(\newcommand{\cN}{\mathcal{N}}\) \(\newcommand{\tensor}{\otimes}\) \(\newcommand{\E}{\mathop{\mathbb{E}}}\) \(\renewcommand{\hat}{\widehat}\) \(\newcommand{\iprod}[1]{\langle #1 \rangle}\) \(\newcommand{\pE}{\tilde{\mathbb{E}}}\) \(\newcommand{\Paren}[1]{\left ( #1 \right )}\) \(\newcommand{\N}{\mathbb{N}}\) \(\newcommand{\Tr}{\text{Tr}}\)
mean estimation with sub-gaussian rates in polynomial time
sam hopkins (miller fellow, uc berkeley)
estimating the mean of a random vector
input: \(X_1,\ldots,X_n \in \R^d\) independent copies of \(X\)
output: estimator \(\hat{\mu}(X_1,\ldots,X_n)\) of \(\mu = \E X\).
for this talk assume isotropic: \(\E (X - \mu)(X - \mu)^\top = I\)
obvious “algorithm” – the empirical mean
empirical mean: \(\overline{\mu} = \tfrac 1 n \sum X_i\)
mean square error: \(\E \| \overline{\mu} - \mu \|^2 = \frac 1 n \E \|X - \mu\|^2 = \frac d n\)
what about the tail?
tail of the empirical mean
how small is \(\Pr(\| \overline{\mu} - \mu \| > t)\)?
confidence interval (c.i.): \(\Pr(\| \overline{\mu} - \mu \| > t) \leq \delta\) implies \(\delta\)-c.i. of width \(t\)
gaussian case:
\(X \sim \cN(\mu, I) \Rightarrow \Pr( \|\overline{\mu} - \mu\| > t + \underbrace{\sqrt{d/n}}_{\approx \E \|\overline{\mu} - \mu \| } ) \leq \underbrace{\exp(-t^2 n)}_{d\text{-independent subgaussian tail}}\)
heavy-tailed case:
covariance \(I \Rightarrow \Pr( \|\overline{\mu} - \mu\| > t ) \leq \underbrace{\frac d {t^2 n}}_{d\text{-dependent fat tail}}\)
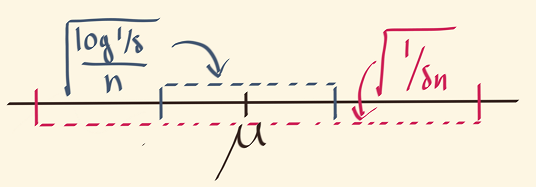
heavy tails
only assume \(\E X, \E X^2\) are finite.
also occur in high dimensions: corruptions, power laws in large networks, etc.
beyond the empirical mean
recall: i.i.d. samples \(X_1,\ldots,X_n\) of \(X\), try to estimate \(\mu = \E X\)
how confident can you be? is there an estimator \(\hat{\mu}\) with \(\Pr( |\hat{\mu} - \mu| > t ) \leq \exp(-\Omega(t^2 n))\) when \(X\) is heavy-tailed?
no. but you can fake it!
theorem (old, \(d=1\)):
for every \(t\), exists \(\hat{\mu}_t\) such that \(\Pr( | \hat{\mu}_t - \mu | > t ) \leq \exp(-\Omega(t^2 n))\)
and \(\hat{\mu}_t\) is poly-time computable
if \(d=1\) can estimate \(\mu\) as if \(X\) were Gaussian, even if only \(\E X, \E X^2\) exist
what happens for \(d > 1\)?
beyond the empirical mean, high dimensions
\(X \sim \cN(\mu, I) \Rightarrow \Pr( \|\overline{\mu} - \mu\| > t + \underbrace{\sqrt{d/n}}_{\approx \E \|\overline{\mu} - \mu \| } ) \leq \underbrace{\exp(-t^2 n)}_{d\text{-independent subgaussian tail}}\)
theorem (lugosi-mendelson, 2018):
for every \(t\), exists \(\hat{\mu}_t\) such that
\[\Pr \left ( \| \hat{\mu}_t - \mu \| > O \left (t + \sqrt{d/n} \right ) \right )\leq \exp(-t^2 n)\]
assuming only \(\E(X-\mu)(X-\mu)^\top = I\).
new combinatorial notion of high-dimensional median, appears to require \(\exp(d)\) time
theorem (this work): same, but \(\hat{\mu}_t\) is computable in time \(O(dn) + (dt)^{O(1)}\)
prior work
covariance \(I\), \(n\) samples
(disclaimer: “tail” not strictly accurate because one estimator \(\hat{\mu}_t\) for each \(t\))
| estimator | dim. | tail | time | ref. |
|---|---|---|---|---|
| empirical mean | any | \(d/t^2 n\) | poly | folklore |
| (many) | \(1\) | \(\exp(-t^2 n)\) | poly | (many) |
| geometric median | any | \(\exp(-t^2 n /d)\) | poly | [Minsker 13, Hsu-Sabato 13] |
| tournament median | any | \(\exp(-t^2 n)\) | exp | [Lugosi-Mendelson 18] |
| median-sdp | any | \(\exp(-t^2 n)\) | poly | this work |
main theorem
theorem: given \(X_1,\ldots,X_n,\delta\), can find \(\hat{\mu}\) such that
\[ \Pr \left ( \left \| \hat{\mu} - \mu \right \| > C \left ( \sqrt{\frac{d}{n}} + \sqrt{\frac{\log(1/\delta)}{n}} \right ) \right ) \leq \delta \, , \]
main innovation: new semidefinite programming (sdp) algorithm for high-dimensional median, based on sum of squares method (sos).
sos familiarity is not a prerequisite for this talk.
agenda
- the \(d=1\) case: median of means
- lugosi and mendelson’s median
- median-sdp
median of means in one dimension
[nemirovsky-yudin, jerrum-valiant-vazirani, alon-matias-szegedy]
\(X_1,\ldots,X_n\) i.i.d. copies of \(X\) with \(\E X = \mu\) and \(\E (X - \mu)^2 = 1\)
empirical mean \(\delta\)-c.i. width \(O\Paren{ \sqrt{\frac{1}{n\delta}}}\)
median of means \(\delta\)-c.i. width \(O \Paren{ \sqrt{\frac{\log(1/\delta)}{n}}}\)
\(1/\delta\) becomes \(\log(1/\delta)\)
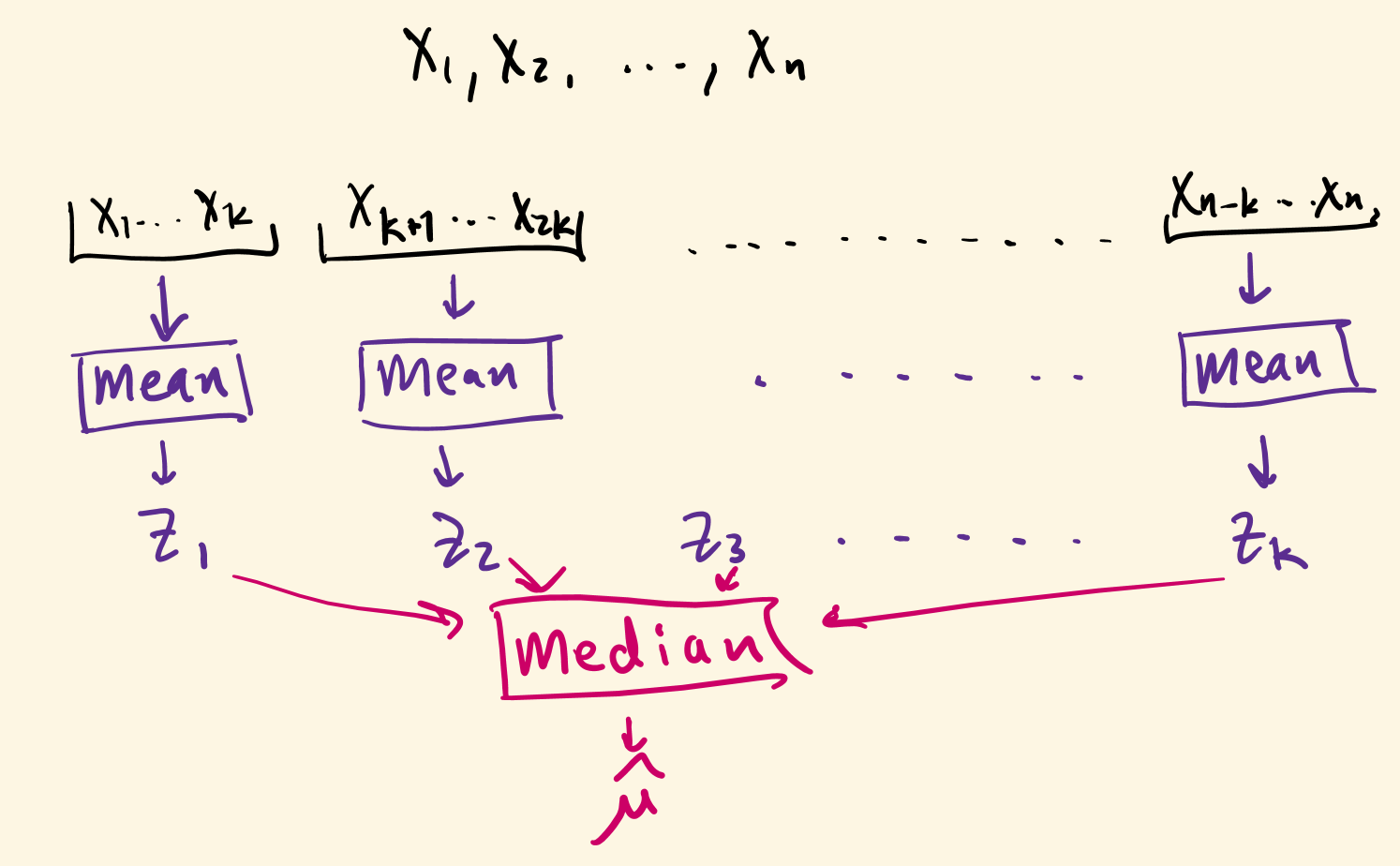
\[k \approx \log(1/\delta)\]



key insight: number of outliers among \(Z_1,\ldots,Z_k\) concentrates even when sum of outliers does not.
median of means in higher dimensions – first attempt
recall gaussian case:
\(X \sim \cN(\mu, I) \Rightarrow \Pr( \|\overline{\mu} - \mu\| > t + \sqrt{d/n} ) \leq \exp(-t^2 n)\)
i.e. \(\delta\)-c.i. radius \(O\Paren{\sqrt{\frac dn} + \sqrt{\frac {\log 1/\delta} n}}\)
goal: match this, only assume \(\E (X - \mu)(X - \mu) = I\)
buckets: \(Z_1,\ldots,Z_k\) with \(\E Z = \mu\) and \(\E (Z - \mu)(Z-\mu)^\top = \Gamma = \tfrac kn I\)
problem: can have \(\|Z_i - \mu\| \approx \sqrt{k d/n}\) for most \(Z_i\)
result: dimension-dependent tail \(\exp(-t^2 n / d)\)
i.e. \(\delta\)-c.i. radius \(O\Paren{\sqrt{\frac{ d \log(1/\delta)}{n}}}\)
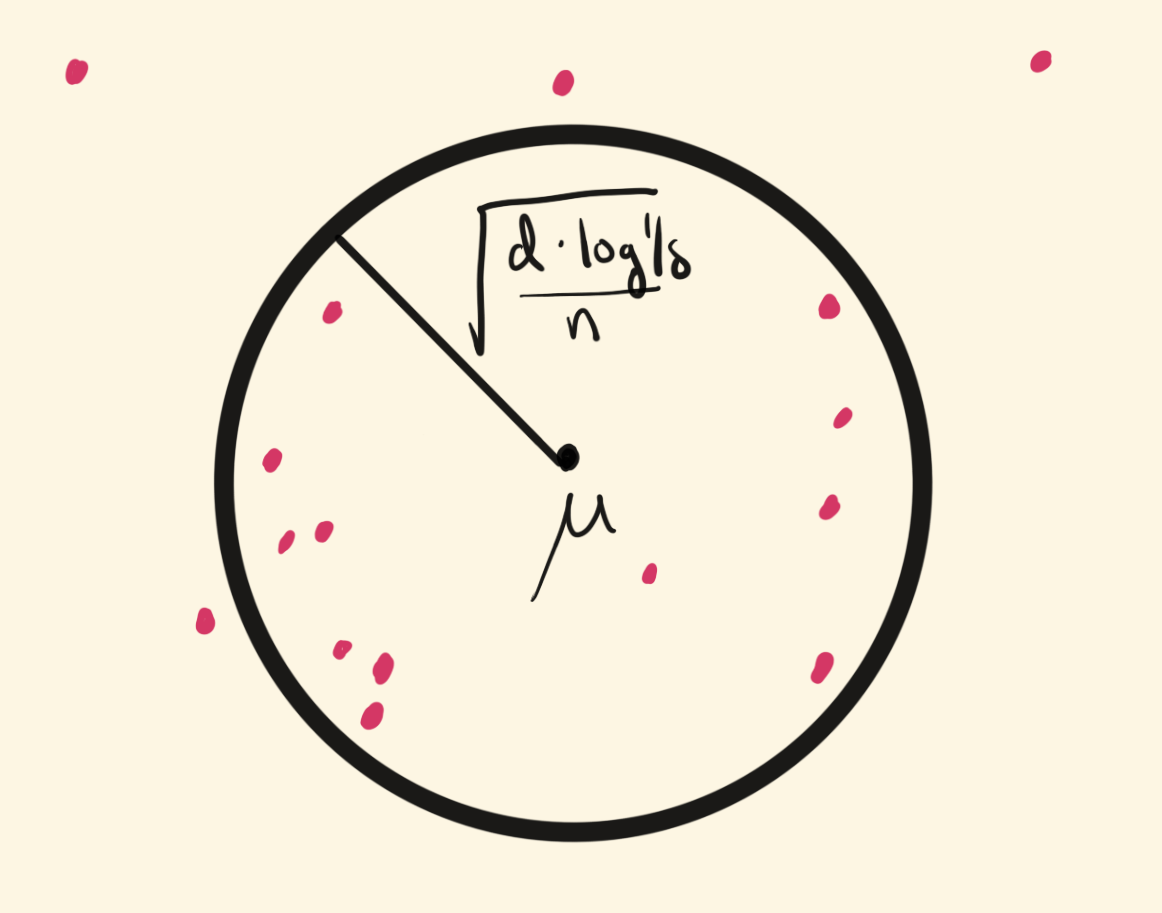
lugosi and mendelson’s median
cannot ask for \(2k/3\) \(Z_i\)’s to be non-outliers
instead, ask for every direction to have at most \(k/3\) outliers!



lugosi and mendelson’s estimator
input: \(X_1,\ldots,X_n,\delta\)
buckets: bucketed means \(Z_1,\ldots,Z_k\) for \(k = \log(1/\delta)\)
centrality: \(x\) is \(r\)-central if in all directions \(u\), for at least \(2k/3\) \(Z_i\),
\(|\iprod{Z_i,u} - \iprod{x,u}| \leq r\)
alternative interpretation: \(x\) is \(r\)-central implies \(x\) has dist. at most \(r\) to a median in every direction
lugosi-mendelson estimator
remember: \(X_1,\ldots,X_n\) samples in \(k = \Theta( \log(1/\delta))\) buckets, \(Z_i\) is mean in \(i\)-th bucket.
output: output \(x \in \R^d\) of “best centrality”
running time??
median sdp
\(10^5\)-foot view
a convex (sdp) relaxation of the set of \(r\)-central \(x\)’s
with enough constraints that each step of the lugosi-mendelson analysis also applies to the sdp (the heart of the “proofs to algorithms” SoS method)
\(\text{poly}(d,k)\) constraints enough to capture all important properties of \(r\)-central points
“approximate” membership test
at the heart of the matter: an sdp for testing \(r\)-centrality
\[ \{ x \, : \, \text{ for all $u$, at most $k/3$ $Z_i$'s have $|\iprod{Z_i,u} - \iprod{x,u}| > r$} \} \]
how would you know if you found such a good \(x\)?
the centrality sdp
given \(x\), start with a quadratic program in \(b = b_1,\ldots,b_k, u = u_1,\ldots,u_d\):
\[\max_{u,b} \sum b_i \text{ such that } b_i^2 = b_i, \|u\|^2 = 1, \text{ and } b_i \iprod{Z_i - x,u} \geq b_i r\]
relax \((b,u)(b,u)^\top\) to block PSD matrix
\[\left ( \begin{array}{cc} B & W \\ W^\top & U \end{array} \right ) \]
\[\begin{align} SDP(Z_1,\ldots,Z_k,\mu) = & \max \, \text{Tr} B \text{ such that} \\ & B_{ii} \leq 1 \\ & \Tr U = 1 \\ & \iprod{Z_i - x, W_i} \geq r B_{ii} \end{align}\]
main challenge: getting it right for \(x = \mu\)
key lemma with high probability, centrality SDP certifies that \(\mu\) is \(r\)-central
proof ideas:
Grothendieck’s inequality to relate sdp to empirical first moment of samples
bounded differences on the sdp itself to get concentration
conclusion
main theorem: first polynomial-time estimator for heavy-tailed estimation matching empirical mean’s performance in Gaussian setting
proof insight: sdps are more outlier robust than averages but can have better statistical rates than trimmed averages or naive medians
open problem: is there a practical algorithm whose empirical performance improves on state-of-the-art for heavy-tailed estimation?
thanks!